728x90
반응형
Dirty Read → commit되지 않은 변화를 읽음.
x= 10, y = 70
Transaction1
- x에 y를 더한다.
Transaction2
- y를 70으로 바꾼다.
시작
- transaction1에서 x를 읽는다. read(x) → 10
- transaction2에서 y를 70으로 바꾼다. write(y=70)
- transaction1에서 다시 x를 읽는다. read(y) → 70
- transaction1에서 x에 y를 더한다. write(x=80)
- transaction1 commit하고 종료
- transaction2에서 abort되어서 rollback되어서 (y=20)
문제점
- transaction1은 write한 70을 읽었는데, transaction2는 Rollback되어서 70은 유효한 값이 아니다.
- 결국 x = 80은 정상적인 값이 아니게 된다.
- 결론적으로 트랜잭션1은 commit되지않은 트랜잭션2의 값을 읽어서 문제 발생.
nonrepeatable read → 같은 데이터의 값이 달라짐.
x = 10
Transaction1
- x를 2번 읽는다.
Transaction2
- x에 40을 더한다.
시작
- transaction1에서 x를 읽는다. read(x) → 10
- transaction2에서 x를 읽는다. read(x) → 10
- transaction2에서 x에 40을 더한다. write(x=50)
- transaction2는 commit
- transaction1에서 x를 읽는다. read(x) → 50
문제점
- 트랜잭션 1번은 한 트랜잭션에서 같은 데이터를 읽었음에도 불구하고 다른값이 나왔다.
- 트랜잭션2에 의해서 x의 값이 바뀌었기 때문이다.
- 이런 현상은 일어나면 안된다. 여러 트랜잭션이 동시에 실행되어도 각각의 트랜잭션이 마치 혼자서 실행되는것처럼 동작해야한다.
phantom read → 없던 데이터가 생김.
t1(v = 10)
t2(v = 50)
Transaction1
- v가 10인 데이터를 두 번 읽는다.
Transaction2
- t2의 v를 10으로 바꾼다.
시작
- Transaction1은 v가 10인 것을 읽는다. read(v=10) → t1
- Transaction2은 t2의 v를 10으로 바꾼다. write(t2.v=10)
- Transaction2 commit
- Transaction1은 v가 10인 것을 읽는다. read(v=10) → t1, t2
문제점
- 트랜잭션1은 동일한 조건으로 두 번 읽었는데, 각각의 결과가 다르다.
- 하나의 트랜잭션에서 같은 조건으로 두번 읽었는데, 두번의 결과가 다르다.
Isolation Level
- 위와 같은 이상한 현상들이 모두 발생하지 않게 만들 수 있지만, 그러면 제약사항이 많아져서 동시 처리 가능한 트랜잭션 수가 줄어들어 결국 DB의 전체 처리량이 하락한다.
- 일부 이상한 허용하는 몇 가지 Level을 만들어서 필요에 따라 적절하게 선택.
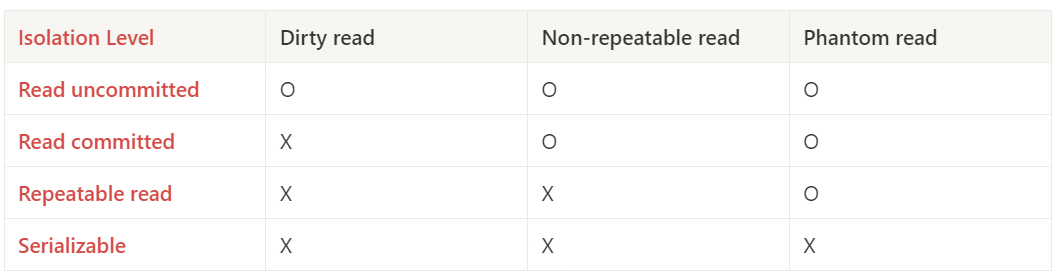
Read uncommitted
- 가장 자유롭지만 이상한 현상에 가장 취약하다. 대신 동시성이 높아져서 전체 처리량은 가장 높다.
- 어떤 트랜잭션에서 작업이 완료되지 않아도 해당 작업을 다른 트랜잭션에서 보는 것이다.
Read committed
- commit된 데이터만 읽는다.
- 온라인 서비스에서 가장 많이 선택되는 격리 수준.
- 어떤 트랜잭션에서 변경한 내용이 커밋되기 전까지는 다른 트랜잭션에서 그러한 변경 내역을 조회할 수 없다.(UNDO 영역의 백업된 레코드에서 결과를 가져온다.)
Serializable(직렬화)
- 아예 이상한 현상 자체가 발생하지 않는 level을 의미.
결론
- 세 가지 이상 현상을 정의하고 어떤 현상을 허용하는지에 따라 각각의 isolation level이 구분.
- 애플리케이션 설계자는 isolation level을 통해 전체 처리량과 데이터 일관성 사이에서 어느정도 거래를 할 수 있다.
Dirty Write → commit 안된 데이터를 write 함.
x=0
Transaction1
- x를 10으로 바꾼다.
Transaction2
- x를 100으로 바꾼다.
시작
- Transaction1은 x를 10으로 바꾼다. write(x=10)
- Transaction2은 x를 100으로 바꾼다. write(x=100)
- Transaction2를 commit
- Transaction1이 abort되어 x가 0으로 바뀜.
문제점
- 트랜잭션2에서 x를 100으로 바꾼게 무용지물된다.
- Rollback시 정상적인 recovery는 매우 중요해서 모든 Isolation Level에서 Dirty Write를 허용하면 안된다.
Lost Update → update가 반영이 안된것.
x=50
Transaction1
- x에 50을 더한다.
Transaction2
- x에 150을 더한다.
시작
- Transaction1에서 x를 읽는다. read(x) → 50
- Transaction2에서 x를 읽는다. read(x) → 50
- Transaction2에서 x에 150을 더한다. write(x=200)
- Transaction2 commit
- Transaction1에서 x에 50을 더한다. write(x=100)
- Transaction1 commit
문제점
- 트랜잭션2에서 write한 값이 사라진다.
- serial 하게 실행되었다면 문제가 없었을텐데, 겹쳐서 실행되어서 문제 발생.
Dirty Read 확장판 → Rollback이 안되어도 문제 발생.
x=50, y=50
Transaction1
- x가 y에 40을 이체한다.
Transaction2
- x와 y를 읽는다.
시작
- Transaction1에서 x를 읽는다. read(x) → 50
- Transaction1에서 x에 40을 뺀다. write(x=10)
- Transaction2에서 x를 읽는다. read(x) → 10
- Transaction2에서 y를 읽는다. read(y) → 50
- Transaction2 commit
- Transaction1에서 y를 읽는다. read(y) → 50
- Transaction1에서 y에 40을 더한다. write(y=90)
- Transaction1 commit
문제점
- x와 y의 합은 100으로 일관성 있게 유지가 되어야하는데, 트랜잭션1에서는 x와 y의 합이 60이다.
- 트랜잭션2는 데이터 정합성이 깨져서 데이터 불일치가 발생.
- abort가 되지 않아도 dirty read가 될 수 있다.
Read Skew → inconsistent한 데이터 읽기
x=50, y=50
Transaction1
- x가 y에 40을 이체
Transaction2
- x와 y를 읽는다.
시작
- Transaction2에서 x를 읽는다. read(x) → 50
- Transaction1에서 x를 읽는다. read(x) → 50
- Transaction1에서 x에 40을 뺀다. write(x=10)
- Transaction1에서 y를 읽는다. read(y) → 50
- Transaction1에서 y에 40을 더한다. write(y=90)
- Transaction2에서 y를 읽는다. read(y) → 90
문제점
- 트랜잭션2에서는 x와 y의 합이 140이 된다.
Write Skew → inconsistent한 데이터 쓰기.
x=50, y=50 ⇒ x+y ≥ 0
Transaction1
- x에서 80을 인출
Transaction2
- y에서 90을 인출
시작
- Transaction1에서 x를 읽는다. read(x) → 50
- Transaction1에서 y를 읽는다. read(y) → 50
- Transaction2에서 x를 읽는다. read(x) → 50
- Transaction2에서 y를 읽는다. read(y) → 50
- Transaction1에서 x에 80을 뺀다. write(x=-30)
- Transaction2에서 y에 90을 뺀다. write(y=-40)
- Transaction1 commit
- Transaction2 commit
문제점
- x+y ≥ 0의 제약사항을 깬다. 데이터 불일치.
Phantom read 확장판
t1(v=7)
cnt = 0 → (v > 10)
Transaction1
- v > 10 데이터와 cnt를 읽는다.
Transaction2
- v=15인 t2를 추가하고 cnt를 1 증가.
시작
- Transaction1에서 v가 10보다 큰 것을 읽는다. → X
- Transaction2에서 v2를 추가. → write(insert t2: v=15)
- Transaction2에서 cnt를 읽는다. → read(cnt) → 0
- Transaction2에서 cnt에 1를 더한다. → write(cnt = 1)
- Transaction2 commit
- Transaction1에서 cnt를 읽는다. read(cnt) → 1
- Transaction1 commit
문제점
- 트랜잭션1에서 처음에 cnt를 읽었을때는 아무것도 없었는데, 나중에는 읽었을때는 생김.
- 결국 데이터 불일치 생김.
SnapShot Isolation → First-committer win
x=50, y=50
Transaction1
- x가 y에 40을 이체.
Transaction2
- y에 100을 입금.
여기에서 트랜잭션 동작은 DB에 반영하는것이 아닌, 스냅샷이라는 공간안에서 반영된다.
시작
- Trnasaction1에서 x를 읽는다. read(x) → 50
- Trnasaction1에서 x에 40을 뺀다. write(x=10) → 스냅샷에 x=10
- Transaction2에서 y를 읽는다. read(y) → 50
- Transaction2에서 y에 100을 더한다. write(y=150) → 스냅샷에 y=150
- Transaction2 commit → DB에 y=150이 적용.
- Transaction1에서 y를 읽는다. read(y) → 50
- 왜냐하면 트랜잭션1에서 시작된 기준으로 보기 때문에 시작된 기준에서 y는 150이 아닌, 50이였기 때문이다.
- Transaction1에서 y에 40을 더한다. write(y=90)
- Transaction1 commit하면 y는 90으로 바뀌어서 트랜잭션2에서 했던 작업이 사라진다. write, write conflict가 발생했을 때 먼저 commit된 트랜잭션만 인정한다. 그래서 나중에 commit하려고 했던 트랜잭션1은 abort 된다. 즉, 트랜잭션 1은 폐기된다.
실무에서 Isolation Level
MySQL(innoDB)
- Serializable, Repeatable Read, Read Committed, Read Uncommitted
- 표준에서 정의한 Isolation Level과 동일하다.
- Repeatable Read는 MySQL의 InnoDB 스토리지 엔진에서 기본적으로 사용되는 격리수준
Oracle
- Read Uncommitted를 제공하지 않는다.
- Repeatable Read 또는 Serializable를 사용하려면 트랜잭션 Isolation Level을 모두 Serializable로 지정해야한다.
- 결국 Oracle에서는 Read Committed랑 Serializable이 주로 사용된다.
- 오라클에서는 Serializable이 스냅샷과 비슷하게 동작한다.
- Read Committed가 기본이다.
SQL server

출처
728x90
반응형
'DataBase' 카테고리의 다른 글
| [DataBase]MVCC (0) | 2023.08.04 |
|---|---|
| [SQL] DDL(Data Define Language) (0) | 2023.03.08 |
| [DB] 데이터베이스 기본개념 (0) | 2023.03.08 |
